Following the larger trends in social psychology, the past few decades in aggression research have been heavily influenced by theories examining the cognitive structures and cognitive processes that contribute to aggressive behavior. Accordingly, researchers have developed several tasks to measure “aggressive cognitions.” Good measures of aggressive cognitions (i.e., those that are reliable and valid) allow researchers to test these social-cognitive theories; bad measures (i.e., unreliable or those lacking validity evidence) do not allow researchers to test these social-cognitive theories.
Recently, we have been looking at the published literature of one commonly-used task for measuring aggressive cognitions: The Aggressive Word Completion Task (AWCT).
The most commonly-used stimuli for this task are freely available here (and have been freely available much longer than OSF has existed), which we think is swell. The posted instructions for using these stimuli recommend that researchers cite Anderson et al. (2003), Anderson et al. (2004), and/or Carnagey and Anderson (2005). After closely examining these three articles, we recommend that researchers NOT cite these articles as evidence for the validity of the AWCT.
What is the AWCT?
When completing the AWCT, participants are presented with several word fragments (e.g., words with one or more missing letters) and are instructed to fill in the missing letters to create a word. Critically, some of the word fragments can be completed with a word that is either semantically associated with the concept of aggression or with a word that is not semantically associated with the concept of aggression. For example, the word fragment “KI_ _” can be completed with aggressive words, such as “KILL” or “KICK”, or it can be completed with non-aggressive words, such as “KITE” or “KISS.” Computationally, the more potentially aggressive word fragments that are completed with aggressive words is considered to indicate more aggressive cognitions.
Thus, the AWCT has several desirable features. First, the AWCT does not require expensive equipment or software. Second, the AWCT can be administered in pencil-paper or online formats. Third, the AWCT is typically described as a task that is widely applicable to a range of research questions. These advantages make the AWCT an easy and flexible task to use.
What is the validity evidence in Anderson et al. (2003), Anderson et al. (2004), and Carnagey and Anderson (2005)?
The earliest published study that used the AWCT is Anderson et al. (2003). Anderson et al. (2003) cites Anderson et al. (2002) as a justification for using the AWCT, which is a manuscript described as “submitted for publication.” Anderson et al. (2002) is eventually published and becomes Anderson et al. (2004). Anderson et al. (2004; which was previously cited as Anderson et al., 2002) then cites Anderson et al. (2003) as justification for using the AWCT.
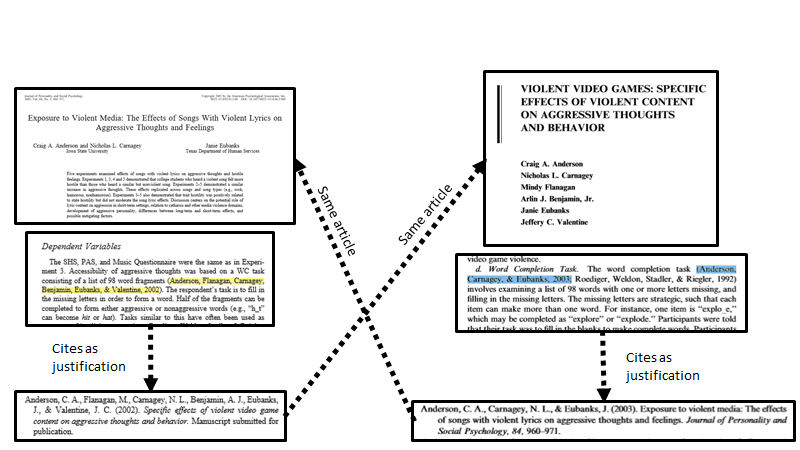
Right off the bat you can see that Anderson et al. (2003) and Anderson et al. (2004) are essentially two studies using one another in a sort of Penrose staircase of justification for using the AWCT.
By 2005, Carnagey and Anderson (2005) describes the AWCT as a “valid measure of aggressive cognitions” and jointly cites Anderson et al. (2003) and Anderson et al. (2004) as justification.

To our eye, there is no independent validation work that is publicly available (which is not to say that any validation work was not done, just that it is not available). These early studies both start using the AWCT and point to themselves as justification for doing so.
The lack of independent validation work is not great news, but it also isn’t inherently damning. The implication is the data from these studies provide some evidence for the validity of the AWCT because these studies purportedly demonstrate the AWCT changes predictably to theoretically-relevant conditions. Indeed, in Anderson et al. (2003), Experiment 4, participants’ trait hostility was associated with their AWCT performance (F [1, 134] = 4.21, p = .042) and participants who were exposed to a song with violent lyrics had higher AWCT performance than two other comparison conditions (F [2, 134] = 3.26, p = .073; note that the authors reported this p-value as being less than .05, which means that either the reported F ratio is incorrect or the reported p-value is incorrect). In Anderson et al. (2003), Experiment 5, participants who were exposed to a song with violent lyrics had higher AWCT performance than those who were exposed to songs without violent lyrics (F [1, 141] = 6.16, p = .014). In Anderson et al. (2004), participants who played a violent video game used more aggressive word completions than participants who played a non-violent video game (F [1, 120] = 4.26, p = .041). And in Carnagey and Anderson (2005), there were main effects for type of video game on aggressive word completions (F [2, 59] = 5.33, p = .007) and baseline systolic blood pressure (F [1, 59] = 5.79, p = .005). However, trait aggression (F [1, 57] = 1.05, p = .31), exposure to video game violence (F [1, 57] = 0.02, p = .89), and video-game ratings (F [1, 59] < 3.10, ps > .08) were not predictors of aggressive word completions.
Notably, in the data from Anderson et al. (2003) and Anderson et al. (2004) is the relevant p-values are all high-yet-significant. Specifically, each p-value is less than .05 and greater than .01. This would be extraordinarily rare if these were all tests of a non-null hypothesis (Simonsohn, Nelson, & Simmons, 2014). In Carnagey and Anderson (2005) there is a mix of significant and non-significant results. Collectively, these results do not strike us as unambiguously supportive of the validity of the AWCT.
However, implicit in these three studies is another form of self-justification for the AWCT. The AWCT is used to test the hypothesis that exposure to violent media (e.g., songs with violent lyrics, violent video games) increase aggressive cognitions. These studies argue that the AWCT is valid because AWCT scores increased after exposure to violent media. Thus, the AWCT is claimed to be a valid measure of aggressive cognitions because it supported these hypotheses AND these hypotheses were claimed to be supported because the AWCT is a valid measure of aggressive cognitions. The claim that violent media increases aggressive cognitions and the claim that the AWCT is a valid measure of aggressive cognitions do not stand independently. Rather, they each rest on the assumption the other is true. In short, this is a form of circular reasoning.
To throw another variable into the mix, let’s look at how the AWCT is administered in these three articles. Anderson et al. (2003) does not impose a time limit for administering the AWCT. Anderson et al. (2004) imposes a 3-minute time limit. Carnagey et al. (2005) imposes a 5-minute time limit. Thus, in these first 3 published studies using the AWCT, there are 3 slightly different procedures used to administer the task. The use of different procedures when administering the AWCT means that the evidence from these studies is not even directly cumulative.
So what?
We are not pointing to this pattern of citations to say “gotcha!” Rather, we are both aggression researchers who really want to ensure that our field is producing the best work possible. And, like a chef who ensures her knives are sharp or a mason who ensures his trowel is not bowed, we believe our best work is possible when we have confidence that our tools work well for the task at hand.
We believe that citing Anderson et al. (2003), Anderson et al. (2004), and Carnagey and Anderson (2005) is merely pointing out that this task has been used in previous publications. However, we believe these articles do not clearly demonstrate the AWCT is a valid measure of aggressive cognitions. In other words, these studies, in and of themselves, do not give us confidence in the AWCT as a useful tool for measuring aggressive cognitions.
Where do we go from here? As suggested by others (e.g., Zendle et al., 2018; see also Koopman et al., 2013), we strongly advocate for rigorous validation work on the AWCT. It may turn out that the AWCT is a valid measure of aggressive cognitions after all. If so, that would be great news. However, it may not. Either way, we need to know.
References
Anderson, C. A., Carnagey, N. L., & Eubanks, J. (2003). Exposure to violent media: The effects of songs with violent lyrics on aggressive thoughts and feelings. Journal of Personality and Social Psychology, 84, 960-971. DOI: 10.1037/0022-3514.84.5.960
Anderson, C. A., Carnagey, N. L., Flanagan, M., Benjamin, A. J., Jr., Eubanks, J., & Valentine, J. C. (2004). Violent video games: Specific effects of violent content on aggressive thoughts and behavior. Advances in Experimental Social Psychology, 36, 199-249. DOI:10.1016/S0065-2601(04)36004-1
Carnagey, N. L., & Anderson, C. A. (2005). The effects of reward and punishment in violent video games on aggressive affect, cognition, and behavior. Psychological Science, 16, 882-889. DOI: 10.1111/j.1467-9280.2005.01632.x
Koopman, J., Howe, M., Johnson, R. E., Tan, J. A., & Chang, C. (2013). A framework for developing word fragment completion tasks. Human Resource Management Review, 23, 242-253. DOI: 10.1016/j.hrmr.2012.12.005
Simonsohn, U., Nelson, L. D., & Simmons, J. P. (2014). p-Curve and effect size: Correcting for publication bias using only significant results. Perspectives on Psychological Science, 9, 666-681. DOI: 10.1177/1745691614553988
Zendle, D., Kudenko, D., & Cairns, P. (2018). Behavioural realism and the activation of aggressive concepts in violent video games. Entertainment Computing, 24, 21-29. DOI: 10.1016/j.entcom.2017.10.003